


Asia Pacific Tele-Ophthalmology Society (APTOS) - Early Detection of Diabetic Retinopathy to Mitigate Vision Loss: A Pre-Blindness Intervention Framework.
About this Competition
A Code Competition to find early prevention solutions.
Each image is labeled with the severity of diabetic retinopathy on a scale of 0 to 4:0 - No DR
1 - Mild
2 - Moderate
3 - Severe
4 - Proliferative DR
Like any real-world data set, we encountered noise in both the images and labels. Images may contain artifacts, be out of focus, underexposed, or overexposed. The images were gathered from multiple clinics using a variety of cameras over an extended period of time, which will introduce further variation.
- Featured Code Competition
Kernel:
Based on kaggle/docker
download the kernel
Approach:
Adaption, comprehension of Hongyi Zhang, MIT - mixup: BEYOND EMPIRICAL RISK MINIMIZATION for image recognition to maximize the score of the quadratically weighted kappa (QWK Evaluation)
Submissions are scored based on the quadratic weighted kappa, which measures the agreement between two ratings. This metric typically varies from 0 (random agreement between raters) to 1 (complete agreement between raters). In the event that there is less agreement between the raters than expected by chance, this metric may go below 0. The quadratic weighted kappa is calculated between the scores assigned by the human rater and the predicted scores.
Images have five possible ratings: 0, 1, 2, 3, 4. Each image is characterized by a tuple (e, e), which corresponds to its scores by Rater A (human) and Rater B (predicted). The quadratic weighted kappa is calculated as follows. First, an $N x N$ histogram matrix $O$ is constructed, such that $O$ corresponds to the number of images that received a rating $i$ by $A$ and a rating $j$ by $B$. An $N-by-N$ matrix of weights, $w$, is calculated based on the difference between raters' scores:
An $N-by-N$ histogram matrix of expected ratings, $E$, is calculated, assuming that there is no correlation between rating scores. This is calculated as the outer product between each rater's histogram vector of ratings, normalized such that $E$ and $O$ have the same sum.
import os
import numpy as np
import pandas as pd
print(os.listdir("../input"))
import cv2
import imgaug as ia
import keras
import matplotlib.pyplot as plt
import PIL
import skimage.io
import tensorflow as tf
from imgaug import augmenters as iaa
from keras import backend as K
from keras import metrics
from keras.applications.densenet import DenseNet121, DenseNet169
from keras.callbacks import ModelCheckpoint
from keras.layers import (
Activation,
BatchNormalization,
Concatenate,
Conv2D,
Dense,
Dropout,
Flatten,
GlobalAveragePooling2D,
GlobalMaxPooling2D,
Input,
concatenate,
)
from keras.losses import binary_crossentropy, categorical_crossentropy
from keras.models import Model, Sequential, load_model
from keras.optimizers import Adam
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import Sequence, to_categorical
from PIL import Image, ImageOps
from skimage.transform import resize
from sklearn.metrics import cohen_kappa_score, f1_score, fbeta_score
from sklearn.model_selection import train_test_split
from sklearn.utils import class_weight, shuffle
from tqdm import tqdm
WORKERS = 2
CHANNEL = 3
import warnings
warnings.filterwarnings("ignore")
SIZE = 300
NUM_CLASSES = 5
df_train = pd.read_csv("../input/aptos2019-blindness-detection/train.csv")
df_test = pd.read_csv("../input/aptos2019-blindness-detection/test.csv")
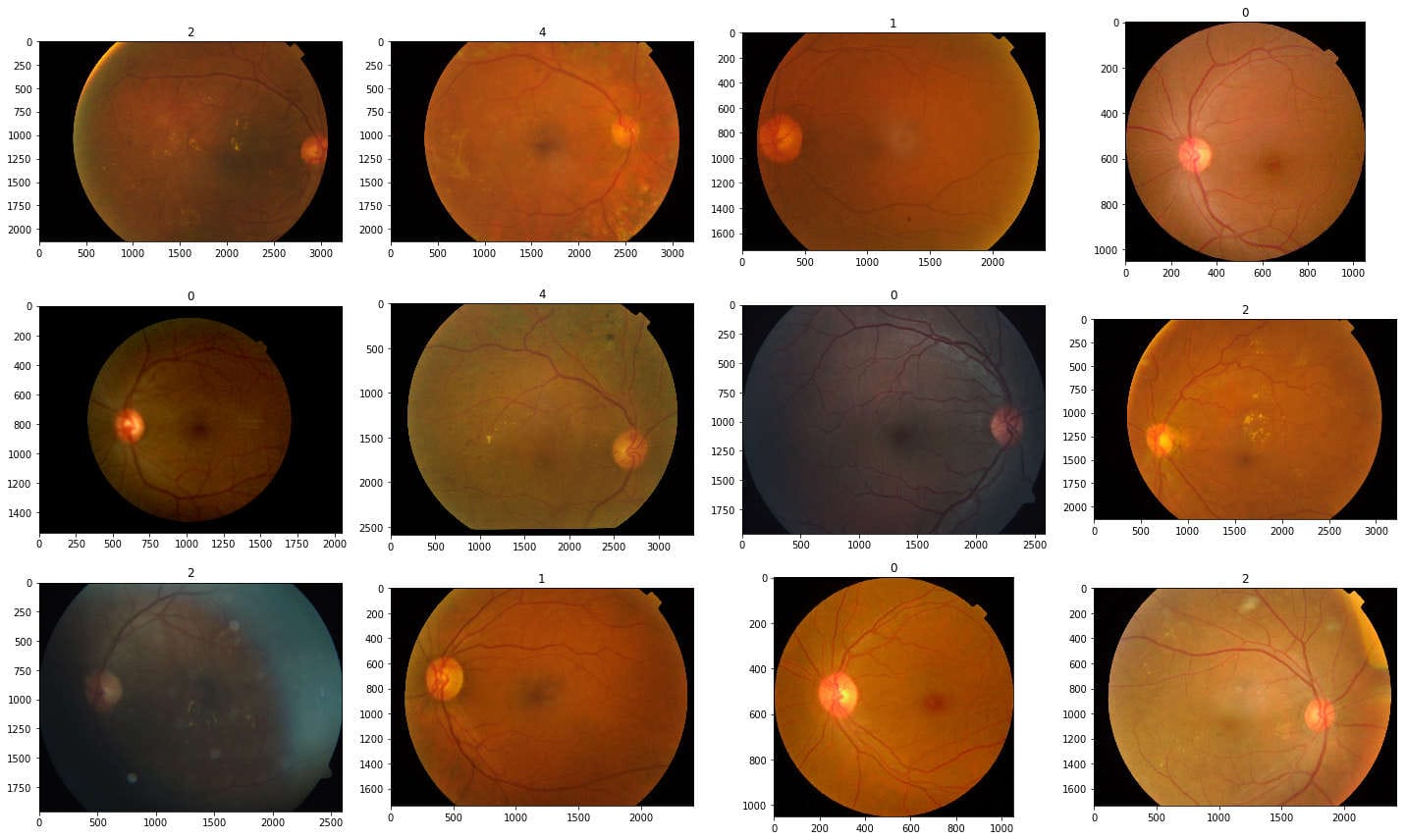
def display_samples(df, columns=4, rows=3):
fig = plt.figure(figsize=(5 * columns, 4 * rows))
for i in range(columns * rows):
image_path = df.loc[i, "id_code"]
image_id = df.loc[i, "diagnosis"]
img = cv2.imread(
f"../input/aptos2019-blindness-detection/train_images/{image_path}.png"
)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
fig.add_subplot(rows, columns, i + 1)
plt.title(image_id)
plt.imshow(img)
plt.tight_layout()
display_samples(df_train)
x = df_train["id_code"]
y = df_train["diagnosis"]
x, y = shuffle(x, y, random_state=8)
y.hist()
Mixup Comprehension
Zhang, Hongyi: mixup: Beyond Empirical Risk Minimization
Large deep neural networks are powerful, but exhibit undesirable behaviors such as memorization and sensitivity to adversarial examples. In this work, we propose mixup, a simple learning principle to alleviate these issues. In essence, mixup trains a neural network on convex combinations of pairs of examples and their labels. By doing so, mixup regularizes the neural network to favor simple linear behavior in- between training examples. Our experiments on the ImageNet-2012, CIFAR-10, CIFAR-100, Google commands and UCI datasets show that mixup improves the generalization of state-of-the-art neural network architectures. We also find that mixup reduces the memorization of corrupt labels, increases the robustness to adversarial examples, and stabilizes the training of generative adversarial networks.
The contribution of this paper is to propose a generic vicinal distribution, called mixup:
$$\mu(\tilde{x},\tilde{y}| x_{i}, y_{i})=\frac{1}{n}\sum_{j}^{n}\mathbb{E_{\lambda}}[\delta(\tilde{x}=\lambda \cdot x_{i}+(1-\lambda) \cdot x_{j},\tilde{y}=\lambda \cdot y_{j}+(1-\lambda) \cdot y_{j})]$$
where $\lambda \sim Beta(\alpha, \alpha)$ for $\alpha \in (0, \infty)$
In a nutshell, sampling from the mixup vicinal distribution produces virtual feature-target vectors
$$\tilde{x}=\lambda x_{i} + (1 - \lambda) x_{j},$$
$$\tilde{y}=\lambda y_{i} + (1 - \lambda) y_{j}$$
Mixup step in PyTorch
# y1, y2 should be one-hot vectors
for(x1, y1), (x2, y2)in zip(loader1, loader2):
lam = numpy.random.beta(alpha, alpha)
x = Variable(lam*x1 + (1. - lam)*x2)
y = Variable(lam*y1 + (1. - lam)*y2)
optimizer.zero_grad()
loss(net(x), y).backward()
optimizer.step()
Training
y = to_categorical(y, num_classes=NUM_CLASSES)
train_x, valid_x, train_y, valid_y = train_test_split(
x,
y,
test_size=0.15,
stratify=y,
random_state=8
)
print(train_x.shape)
print(train_y.shape)
print(valid_x.shape)
print(valid_y.shape)
Image Augmentation
sometimes = lambda aug: iaa.Sometimes(0.5, aug)
seq = iaa.Sequential(
[
iaa.Fliplr(0.5),
iaa.Flipud(0.2),
sometimes(
iaa.Affine(
scale={"x": (0.9, 1.1), "y": (0.9, 1.1)},
translate_percent={"x": (-0.1, 0.1), "y": (-0.1, 0.1)},
rotate=(-10, 10),
shear=(-5, 5),
order=[0, 1],
cval=(0, 255),
mode=ia.ALL,
)
),
iaa.SomeOf(
(0, 5),
[
sometimes(iaa.Superpixels(p_replace=(0, 1.0), n_segments=(20, 200))),
iaa.OneOf(
[
iaa.GaussianBlur((0, 1.0)),
iaa.AverageBlur(k=(3, 5)),
iaa.MedianBlur(k=(3, 5)),
]
),
iaa.Sharpen(alpha=(0, 1.0), lightness=(0.9, 1.1)),
iaa.Emboss(alpha=(0, 1.0), strength=(0, 2.0)),
iaa.SimplexNoiseAlpha(
iaa.OneOf(
[
iaa.EdgeDetect(alpha=(0.5, 1.0)),
iaa.DirectedEdgeDetect(
alpha=(0.5, 1.0), direction=(0.0, 1.0)
),
]
)
),
iaa.AdditiveGaussianNoise(
loc=0, scale=(0.0, 0.01 * 255), per_channel=0.5
),
iaa.OneOf(
[
iaa.Dropout((0.01, 0.05), per_channel=0.5),
iaa.CoarseDropout(
(0.01, 0.03), size_percent=(0.01, 0.02), per_channel=0.2
),
]
),
iaa.Invert(0.01, per_channel=True),
iaa.Add((-2, 2), per_channel=0.5),
iaa.AddToHueAndSaturation((-1, 1)),
iaa.OneOf(
[
iaa.Multiply((0.9, 1.1), per_channel=0.5),
iaa.FrequencyNoiseAlpha(
exponent=(-1, 0),
first=iaa.Multiply((0.9, 1.1), per_channel=True),
second=iaa.ContrastNormalization((0.9, 1.1)),
),
]
),
sometimes(iaa.ElasticTransformation(alpha=(0.5, 3.5), sigma=0.25)),
sometimes(iaa.PiecewiseAffine(scale=(0.01, 0.05))),
sometimes(iaa.PerspectiveTransform(scale=(0.01, 0.1))),
],
random_order=True,
),
],
random_order=True,
)
Custom Generator Class
class My_Generator(Sequence):
def __init__(
self,
image_filenames,
labels,
batch_size,
is_train=True,
mix=False,
augment=False,
):
self.image_filenames, self.labels = image_filenames, labels
self.batch_size = batch_size
self.is_train = is_train
self.is_augment = augment
if self.is_train:
self.on_epoch_end()
self.is_mix = mix
def __len__(self):
return int(np.ceil(len(self.image_filenames) / float(self.batch_size)))
def __getitem__(self, idx):
batch_x = self.image_filenames[
idx * self.batch_size : (idx + 1) * self.batch_size
]
batch_y = self.labels[idx * self.batch_size : (idx + 1) * self.batch_size]
if self.is_train:
return self.train_generate(batch_x, batch_y)
return self.valid_generate(batch_x, batch_y)
def on_epoch_end(self):
if self.is_train:
self.image_filenames, self.labels = shuffle(
self.image_filenames, self.labels
)
else:
pass
Mixup Algorithm
$$\mu(\tilde{x},\tilde{y}| x_{i}, y_{i})=\frac{1}{n}\sum_{j}^{n}\mathbb{E_{\lambda}}[\delta(\tilde{x}=\lambda \cdot x_{i}+(1-\lambda) \cdot x_{j},\tilde{y}=\lambda \cdot y_{j}+(1-\lambda) \cdot y_{j})]$$
def mix_up(self, x, y):
lam = np.random.beta(0.2, 0.4)
ori_index = np.arange(int(len(x)))
index_array = np.arange(int(len(x)))
np.random.shuffle(index_array)
mixed_x = lam * x[ori_index] + (1 - lam) * x[index_array]
mixed_y = lam * y[ori_index] + (1 - lam) * y[index_array]
return mixed_x, mixed_y
Generate batches
def train_generate(self, batch_x, batch_y):
batch_images = []
for sample, label in zip(batch_x, batch_y):
img = cv2.imread(
"../input/aptos2019-blindness-detection/train_images/" + sample + ".png"
)
img = cv2.resize(img, (SIZE, SIZE))
if self.is_augment:
img = seq.augment_image(img)
batch_images.append(img)
batch_images = np.array(batch_images, np.float32) / 255
batch_y = np.array(batch_y, np.float32)
if self.is_mix:
batch_images, batch_y = self.mix_up(batch_images, batch_y)
return batch_images, batch_y
def valid_generate(self, batch_x, batch_y):
batch_images = []
for sample, label in zip(batch_x, batch_y):
img = cv2.imread(
"../input/aptos2019-blindness-detection/train_images/" + sample + ".png"
)
img = cv2.resize(img, (SIZE, SIZE))
batch_images.append(img)
batch_images = np.array(batch_images, np.float32) / 255
batch_y = np.array(batch_y, np.float32)
return batch_images, batch_y
Create the model
def create_model(input_shape, n_out):
input_tensor = Input(shape=input_shape)
base_model = DenseNet121(include_top=False, weights=None, input_tensor=input_tensor)
base_model.load_weights("../input/densenet-keras/DenseNet-BC-121-32-no-top.h5")
x = GlobalAveragePooling2D()(base_model.output)
x = Dropout(0.5)(x)
x = Dense(1024, activation="relu")(x)
x = Dropout(0.5)(x)
final_output = Dense(n_out, activation="softmax", name="final_output")(x)
model = Model(input_tensor, final_output)
return model
# create callbacks list
from keras.callbacks import (
CSVLogger,
EarlyStopping,
LearningRateScheduler,
ModelCheckpoint,
ReduceLROnPlateau,
)
epochs = 30
batch_size = 32
checkpoint = ModelCheckpoint(
"../working/densenet_.h5",
monitor="val_loss",
verbose=1,
save_best_only=True,
mode="min",
save_weights_only=True,
)
reduceLROnPlat = ReduceLROnPlateau(
monitor="val_loss", factor=0.5, patience=4, verbose=1, mode="auto", epsilon=0.0001
)
early = EarlyStopping(monitor="val_loss", mode="min", patience=9)
csv_logger = CSVLogger(
filename="../working/training_log.csv", separator=",", append=True
)
train_generator = My_Generator(train_x, train_y, 128, is_train=True)
train_mixup = My_Generator(
train_x, train_y, batch_size, is_train=True, mix=False, augment=True
)
valid_generator = My_Generator(valid_x, valid_y, batch_size, is_train=False)
model = create_model(input_shape=(SIZE, SIZE, 3), n_out=NUM_CLASSES)
Kappa loss function
reference link: https://www.kaggle.com/christofhenkel/weighted-kappa-loss-for-keras-tensorflow
def kappa_loss(y_true, y_pred, y_pow=2, eps=1e-12, N=5, bsize=32, name="kappa"):
"""A continuous differentiable approximation of discrete kappa loss.
Args:
y_pred: 2D tensor or array, [batch_size, num_classes]
y_true: 2D tensor or array,[batch_size, num_classes]
y_pow: int, e.g. y_pow=2
N: typically num_classes of the model
bsize: batch_size of the training or validation ops
eps: a float, prevents divide by zero
name: Optional scope/name for op_scope.
Returns:
A tensor with the kappa loss."""
with tf.name_scope(name):
y_true = tf.to_float(y_true)
repeat_op = tf.to_float(tf.tile(tf.reshape(tf.range(0, N), [N, 1]), [1, N]))
repeat_op_sq = tf.square((repeat_op - tf.transpose(repeat_op)))
weights = repeat_op_sq / tf.to_float((N - 1) ** 2)
pred_ = y_pred**y_pow
try:
pred_norm = pred_ / (eps + tf.reshape(tf.reduce_sum(pred_, 1), [-1, 1]))
except Exception:
pred_norm = pred_ / (eps + tf.reshape(tf.reduce_sum(pred_, 1), [bsize, 1]))
hist_rater_a = tf.reduce_sum(pred_norm, 0)
hist_rater_b = tf.reduce_sum(y_true, 0)
conf_mat = tf.matmul(tf.transpose(pred_norm), y_true)
nom = tf.reduce_sum(weights * conf_mat)
denom = tf.reduce_sum(
weights
* tf.matmul(
tf.reshape(hist_rater_a, [N, 1]), tf.reshape(hist_rater_b, [1, N])
)
/ tf.to_float(bsize)
)
return (
nom * 0.5 / (denom + eps) + categorical_crossentropy(y_true, y_pred) * 0.5
)
Quadratically Weighted Kappa Evaluation
from keras.callbacks import Callback
class QWKEvaluation(Callback):
def __init__(self, validation_data=(), batch_size=64, interval=1):
super(Callback, self).__init__()
self.interval = interval
self.batch_size = batch_size
self.valid_generator, self.y_val = validation_data
self.history = []
def on_epoch_end(self, epoch, logs={}):
if epoch % self.interval == 0:
y_pred = self.model.predict_generator(
generator=self.valid_generator,
steps=np.ceil(float(len(self.y_val)) / float(self.batch_size)),
workers=1,
use_multiprocessing=False,
verbose=1,
)
def flatten(y):
return np.argmax(y, axis=1).reshape(-1)
score = cohen_kappa_score(
flatten(self.y_val),
flatten(y_pred),
labels=[0, 1, 2, 3, 4],
weights="quadratic",
)
print("\n epoch: %d - QWK_score: %.6f \n" % (epoch + 1, score))
self.history.append(score)
if score >= max(self.history):
print("saving checkpoint: ", score)
self.model.save("../working/densenet_bestqwk.h5")
qwk = QWKEvaluation(
validation_data=(valid_generator, valid_y), batch_size=batch_size, interval=1
)
Compile the Model
# warm up model
for layer in model.layers:
layer.trainable = False
for i in range(-3, 0):
model.layers[i].trainable = True
model.compile(loss="categorical_crossentropy", optimizer=Adam(1e-3))
model.fit_generator(
train_generator,
steps_per_epoch=np.ceil(float(len(train_y)) / float(128)),
epochs=5,
workers=WORKERS,
use_multiprocessing=True,
verbose=1,
callbacks=[qwk],
)
Train all layers
for layer in model.layers:
layer.trainable = True
callbacks_list = [checkpoint, csv_logger, reduceLROnPlat, early, qwk]
model.compile(loss="categorical_crossentropy", optimizer=Adam(lr=1e-4))
model.fit_generator(
train_mixup,
steps_per_epoch=np.ceil(float(len(train_x)) / float(batch_size)),
validation_data=valid_generator,
validation_steps=np.ceil(float(len(valid_x)) / float(batch_size)),
epochs=epochs,
verbose=1,
workers=1,
use_multiprocessing=False,
callbacks=callbacks_list,
)
submit = pd.read_csv("../input/aptos2019-blindness-detection/sample_submission.csv")
model.load_weights("../working/densenet_bestqwk.h5")
predicted = []
for i, name in tqdm(enumerate(submit["id_code"])):
path = os.path.join(
"../input/aptos2019-blindness-detection/test_images/", name + ".png"
)
image = cv2.imread(path)
image = cv2.resize(image, (SIZE, SIZE))
X = np.array((image[np.newaxis]) / 255)
score_predict = (
(
model.predict(X).ravel()
* model.predict(X[:, ::-1, :, :]).ravel()
* model.predict(X[:, ::-1, ::-1, :]).ravel()
* model.predict(X[:, :, ::-1, :]).ravel()
)
** 0.25
).tolist()
label_predict = np.argmax(score_predict)
predicted.append(str(label_predict))
submit["diagnosis"] = predicted
submit.to_csv("submission.csv", index=False)
submit.head()
Results:
"I also would like to thank those who generously contributed in the kernels and discussions in this competition, and to the top teams that shared solutions and findings in the 2015 competition. Those findings and solutions have greatly impacted my strategy."
– Guanshuo Xu
Yes, I would like to conclude with falling into line with this statement and share my humble metrics below.
Leaderboard Score:
| # | ∆pub | name | score (QWK) |
|---|---|---|---|
| 1089 | 538 | __ministry__ |
0.903397 |
Kernel Score
| Private Score | 0.872168 |
| Public Score | 0.720587 |
Execution Info:
| Succeeded | True | Run Time | 23809.5 seconds |
| Exit Code | 0 | Timeout Exceeded | False |
| Used All Space | False | Output Size | 125.29 MB |
| Environment | Docker Image | Accelerator | GPU |


