



Series I–IX. On a sketch, a prompt, and what the model finds when you stop telling it what to look for.
The Sketch
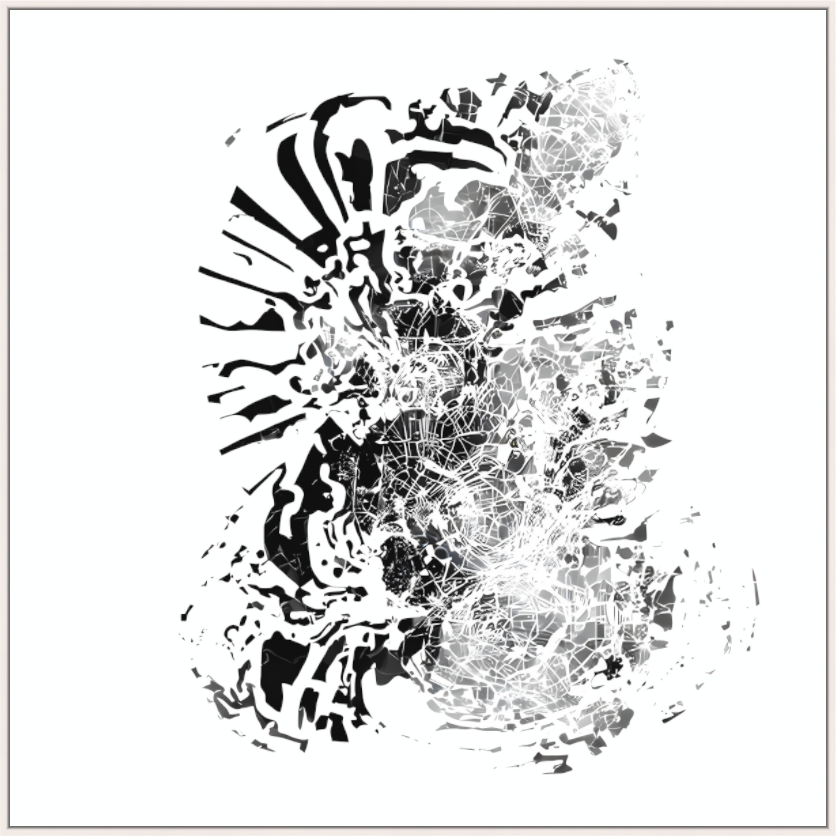
Everything begins with a hand-drawn ink sketch — a single subconscious mark, made in minutes, carrying a lot of representational intent, almost a symbol of a signature. However — no face, no building, no landscape. An abstract symbol on paper.
This sketch becomes the seed for everything that follows. Fed into Stable Diffusion with ControlNet, it is the fixed input that the system interprets, reinterprets, and transforms across hundreds of iterations over several weeks. The prompt is reduced to two words: intergalactic frequencies. Nothing else. No style instructions, no subject descriptions, no compositional guidance.
Stripping the prompt to a minimum was an experimental condition: what does a generative model do when the human stops telling it what to see?
What the Model Found
The answer was unexpected on two levels.
First: the less specific the prompt, the more diverse and structurally surprising the outputs became. High-guidance runs with detailed prompts produced predictable results — competent, coherent, dead. Low-guidance runs with the two-word prompt produced images that no one had asked for: emergent symmetries, spatial structures that felt architectural without being buildings, textures that oscillated between organic and crystalline.
Second, and more interesting: the model consistently introduced faces. No face was specified. No facial reference existed in the input sketch. But across iterations, facial structures appeared — fragmented, morphed, sometimes barely recognizable, but persistent. The network, trained on millions of images in which faces are statistically dominant, gravitates toward the human form even when nothing in the input calls for it. Bias made visible — the training data expressing itself through the absence of instruction.
The early runs used extended prompts — mycelium structures, vanishing points, consciousness, octane render, Yoshitaka Amano — at high guidance scales. The results were illustrative and controlled. The project only became interesting when this scaffolding was removed. Two words. Low guidance. The sketch as anchor.
A detailed prompt tells the model what to produce. A minimal prompt asks the model what it finds. The human provides the constraint, the network provides the interpolation.
The Process
The technical pipeline has four stages, each serving a distinct function:
Generation. The ink sketch is processed through ControlNet (Canny, OpenPose, Depth, and others) with Stable Diffusion v1.5. Parameters are tuned across runs — inference steps between 60 and 100, guidance scale between 5 and 15, multiple samplers tested. Generated images are fed back as inputs for subsequent iterations, creating a feedback loop in which each generation builds on the last.
Selection. From hundreds of generated images, a subset is chosen — not for technical quality (many technically clean images are discarded), but for whether the image carries something the artist did not put there and yet recognizes as meaningful. This step cannot be automated. It is somatic judgment: the felt sense, below the threshold of articulation, that this one matters.
Sorting. The selected images are processed through ResNet50 (TensorFlow) to establish similarity relationships between frames. An alternative approach — tiling images and clustering regions by feature similarity — was tested and abandoned; it fragmented the sequences and destroyed continuity. The holistic sorting with ResNet50 preserved the visual arc.
Morphing. Adobe AfterEffects with time-warping techniques bridges the gaps between frames, creating the illusion of continuous motion. The limitations are visible — some frames are skipped, some transitions stutter. A next stage, currently in development, involves training a dedicated interpolation network to generate intermediate frames, achieving smoother transitions within the evolving visual logic.
The results are nine short sequences, published as experimental video works.
What the Imperfections Carry
Generative AI discourse is dominated by the pursuit of photorealism — better faces, better hands, fewer artifacts. The entire evaluation framework assumes that the model's job is to simulate reality, and that deviations from simulation are failures.
Intergalactic Frequencies takes the opposite position. The distorted hands, the morphed faces, the non-human features, the spatial impossibilities — these are the signature of a process freed from the obligation to represent. What the network produces when realism is off the table.
This is not a defense of sloppiness. The imperfections carry information. A morphed face tells you something about how the model encodes facial structure — which features it considers load-bearing, which it lets drift. A spatial impossibility tells you something about how the network handles depth without explicit 3D modeling. The artifacts are a readout of the model's internal geometry, made visible precisely because the guidance is low enough to let the latent space express itself.
The project's aesthetic is closer to radiography than to painting. The images show how a network processes visual information when seeing is unconstrained — the latent space expressing itself through the artifacts.
The Authorship Question
There is a defensive reflex in most writing about AI art: the insistence that the human is the real author, the AI is merely a tool, and nothing fundamental has changed about creative agency. This reflex is understandable. It is also insufficient.
The honest description: the hand-drawn sketch is the author's. The two-word prompt is the author's. The parameter decisions are the author's. The selection — hours of choosing which images survive and which are discarded — is unambiguously the author's. The images themselves are produced by a system whose internal operations are opaque, whose outputs are unpredictable from its inputs, whose "decisions" are statistical.
The more honest description: the author sets the conditions. The network generates within those conditions. The author selects from the generation. The authorship is distributed across the setting, the generating, and the selecting — and the generating is the one part the author does not control.
That is how the work gets made. It aligns with an understanding of creative work older than the Romantic model of the solitary genius: making things involves submitting to processes you do not fully control — the grain of the wood, the chemistry of the glaze, the resistance of the stone. The work emerges in the encounter between intention and material.
The difference with AI is scale. The material is not passive. It interpolates. It hallucinates. It introduces structure the author did not request. The encounter is more active, the material more generative, than wood or stone. But the structure of the encounter — set conditions, engage material, select results — is the same structure it has always been.
Technical parameters, process documentation, and the full nine-part series are available on the project page. Selected editions available on mintbase.xyz. Edit: mintbase.xyz has been discontinued. How ironic.
References: Stable Diffusion v1.5 (Rombach et al., 2022). ControlNet (Zhang & Agrawala, 2023). ResNet50 (He et al., 2016). TensorFlow image similarity pipeline. Adobe AfterEffects time-warp interpolation.
Series I


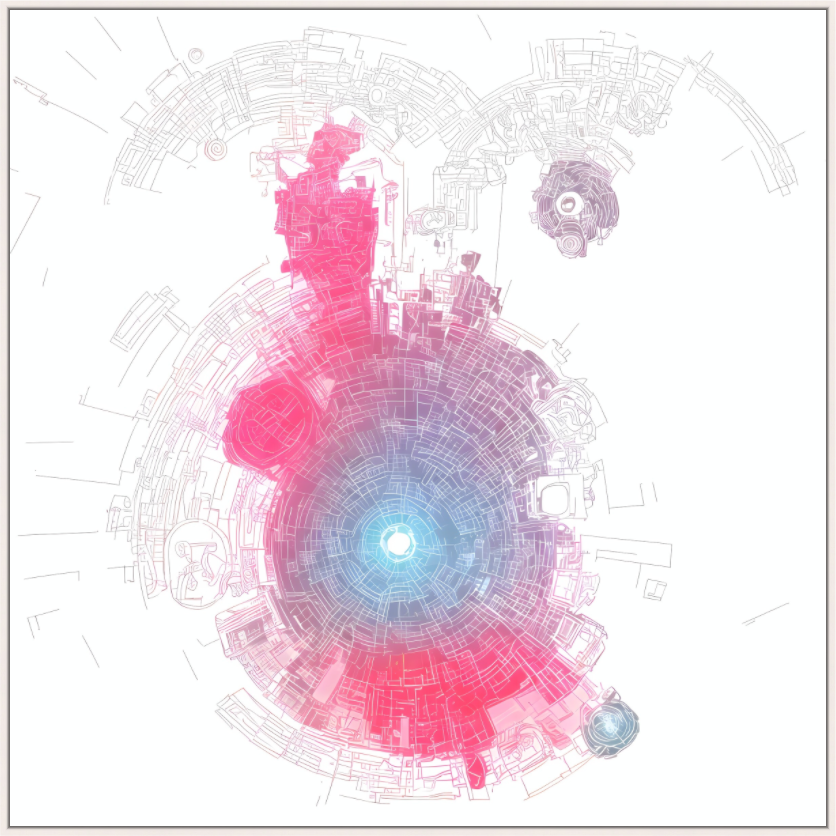


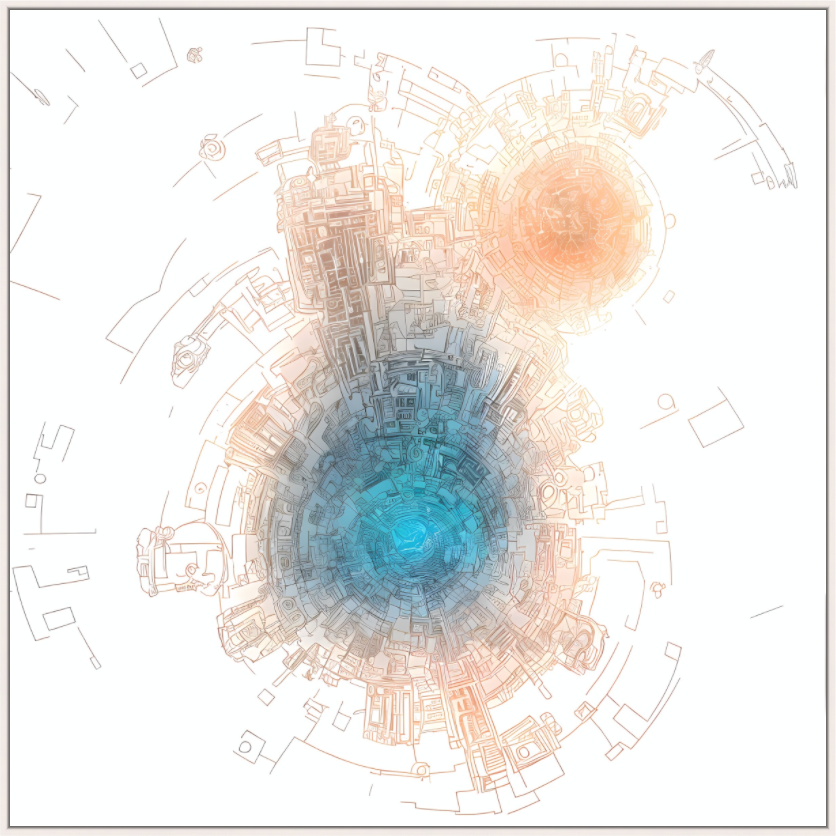




Series II




Series III















Series IV